Выборочное наблюдение в статистике. Выборка (Выборочная совокупность)
Выборочное наблюдение применяется, когда применение сплошного наблюдения физически невозможно из-за большого массива данных или экономически нецелесообразно . Физическая невозможность имеет место, например, при изучении пассажиропотоков, рыночных цен, семейных бюджетов. Экономическая нецелесообразность имеет место при оценке качества товаров, связанной с их уничтожением, например, дегустация, испытание кирпичей на прочность и т.п.
Статистические единицы, отобранные для наблюдения, составляют выборочную совокупность или выборку , а весь их массив - генеральную совокупность (ГС). При этом число единиц в выборке обозначают n , а во всей ГС - N . Отношение n/N называется относительный размер или доля выборки .
Качество результатов выборочного наблюдения зависит от репрезентативности выборки , то есть от того, насколько она представительна в ГС. Для обеспечения репрезентативности выборки необходимо соблюдать принцип случайности отбора единиц , который предполагает, что на включение единицы ГС в выборку не может повлиять какой-либо иной фактор кроме случая.
Существует 4 способа случайного отбора в выборку:
- Собственно случайный отбор или «метод лото», когда статистическим величинам присваиваются порядковые номера, заносимые на определенные предметы (например, бочонки), которые затем перемешиваются в некоторой емкости (например, в мешке) и выбираются наугад. На практике этот способ осуществляют с помощью генератора случайных чисел или математических таблиц случайных чисел.
- Механический отбор, согласно которому отбирается каждая (N/n )-я величина генеральной совокупности. Например, если она содержит 100 000 величин, а требуется выбрать 1 000, то в выборку попадет каждая 100 000 / 1000 = 100-я величина. Причем, если они не ранжированы, то первая выбирается наугад из первой сотни, а номера других будут на сотню больше. Например, если первой оказалась единица № 19, то следующей должна быть № 119, затем № 219, затем № 319 и т.д. Если единицы генеральной совокупности ранжированы, то первой выбирается № 50, затем № 150, затем № 250 и так далее.
- Отбор величин из неоднородного массива данных ведется стратифицированным (расслоенным) способом, когда генеральная совокупность предварительно разбивается на однородные группы, к которым применяется случайный или механический отбор.
- Особый способ составления выборки представляет собой серийный отбор, при котором случайно или механически выбирают не отдельные величины, а их серии (последовательности с какого-то номера по какой-то подряд), внутри которых ведут сплошное наблюдение.
Качество выборочных наблюдений зависит и от типа выборки
: повторная
или бесповторная.
При повторном отборе
попавшие в выборку статистические величины или их серии после использования возвращаются в генеральную совокупность, имея шанс попасть в новую выборку. При этом у всех величин генеральной совокупности одинаковая вероятность включения в выборку.
Бесповторный отбор
означает, что попавшие в выборку статистические величины или их серии после использования не возвращаются в генеральную совокупность, а потому для остальных величин последней повышается вероятность попадания в следующую выборку.
Бесповторный отбор дает более точные результаты, поэтому применяется чаще. Но есть ситуации, когда его применить нельзя (изучение пассажиропотоков, потребительского спроса и т.п.) и тогда ведется повторный отбор.
Ошибки выборки
Выборочную совокупность можно сформировать по количественному признаку статистических величин, а также по альтернативному или атрибутивному. В первом случае обобщающей характеристикой выборки служит величина, обозначаемая , а во втором — выборочная доля величин, обозначаемая w . В генеральной совокупности соответственно: генеральная средняя и генеральная доля р .
Разности — и W — р называются ошибкой выборки , которая делится на ошибку регистрации и ошибку репрезентативности . Первая часть ошибки выборки возникает из-за неправильных или неточных сведений по причинам непонимания существа вопроса, невнимательности регистратора при заполнении анкет, формуляров и т.п. Она достаточно легко обнаруживается и устраняется. Вторая часть ошибки возникает из-за постоянного или спонтанного несоблюдения принципа случайности отбора. Ее трудно обнаружить и устранить, она гораздо больше первой и потому ей уделяется основное внимание.
Величина ошибки выборки может быть разной для разных выборок из одной генеральной совокупности, поэтому в статистике определяется средняя ошибка повторной и бесповторной выборки по формулам:
Повторная;
 - бесповторная;
- бесповторная;
Где Дв - выборочная дисперсия .
Например, на заводе с численностью работников 1000 чел. проведена 5%-ая случайная бесповторная выборка с целью определения среднего стажа работников. Результаты выборочного наблюдения приведены в первых двух столбцах следующей таблицы:В 3-м столбце определены середины интервалов X (как полусумма нижней и верхней границ интервала), а в 4-м столбце - произведения X И f для нахождения выборочной средней по формуле средней арифметической взвешенной :
X , лет
(стаж работы)f , чел.
(число работников в выборке)X и
X иf
143,0/50 = 2,86 (года).
Рассчитаем выборочную дисперсию взвешенную:
= 105,520/50 = 2,110.
Теперь найдем среднюю ошибку бесповторной выборки:
= 0,200 (лет).
Из формул средних ошибок выборки видно, что ошибка меньше при бесповторной выборке, и, как доказано в теории вероятностей, она возникает с вероятностью 0,683 (то есть если провести 1000 выборок из одной генеральной совокупности, то в 683 из них ошибка не превзойдет средней ошибки выборки). Такая вероятность (0,683) является невысокой, поэтому она мало пригодна для практических расчетов, где нужна более высокая вероятность. Чтобы определить ошибку выборки с более высокой, чем 0,683 вероятностью, рассчитывают предельную ошибку выборки :
Где t – коэффициент доверия, зависящий от вероятности, с которой определяется предельная ошибка выборки.
Значения коэффициента доверия t рассчитаны для разных вероятностей и имеются в специальных таблицах (интеграл Лапласа), из которых в статистике широко применяются следующие сочетания:
| Вероятность | 0,683 | 0,866 | 0,950 | 0,954 | 0,988 | 0,990 | 0,997 | 0,999 |
| t | 1 | 1,5 | 1,96 | 2 | 2,5 | 2,58 | 3 | 3,5 |
Задавшись конкретным уровнем вероятности, выбирают из таблицы соответствующую ей величину t
и определяют предельную ошибку выборки по формуле.
При этом чаще всего применяют = 0,95 и t
= 1,96, то есть считают, что с вероятностью 95% предельная ошибка выборки в 1,96 раза больше средней. Такая вероятность (0,95) считается стандартной
и применяется по умолчанию в расчетах.
В нашем , определим предельную ошибку выборки при стандартной 95%-ой вероятности (из берем t = 1,96 для 95%-ой вероятности): = 1,96*0,200 = 0,392 (года).
После расчета предельной ошибки находят доверительный интервал обобщающей характеристики генеральной совокупности
. Такой интервал для генеральной средней величины имеет вид
То есть средний стаж работников на всем заводе лежит в интервале от 2,468 года до 3,252 года.
Определение численности выборки
Разрабатывая программу выборочного наблюдения, иногда задаются конкретным значением предельной ошибки с уровнем вероятности. Неизвестной остается минимальная численность выборки, обеспечивающая заданную точность. Ее можно получить из формул средней и предельной ошибок в зависимости от типа выборки. Так, подставляя и в и, решая ее относительно численности выборки, получим следующие формулы:
для повторной выборки n
=
для бесповторной выборки n
= .
Кроме того, при статистических величинах с количественными признаками надо знать и выборочную дисперсию, но к началу расчетов и она не известна. Поэтому она принимается приближенно одним из следующих способов (в приоритетном порядке):
При изучении не численных признаков, если даже нет приблизительных сведений о выборочной доле, принимается w = 0,5, что по формуле дисперсии доли соответствует выборочной дисперсии в максимальном размере Дв = 0,5*(1-0,5) = 0,25.
Один из главных компонентов тщательно продуманного исследования – определение выборки и что такое репрезентативная выборка. Это как в примере с тортом. Ведь не обязательно съедать весь десерт, чтобы понять его вкус? Достаточно небольшой части.
Так вот, торт – это генеральная совокупность (то есть все респонденты, которые подходят для опроса). Она может быть выражена территориально, например, лишь жители Московской области. Гендерно – только женщины. Или иметь ограничения по возрасту – россияне старше 65 лет.
Высчитать генеральную совокупность сложно: нужно иметь данные переписи населения или предварительных оценочных опросов. Поэтому обычно генеральную совокупность «прикидывают», а из полученного числа высчитывают выборочную совокупность или выборку .
Что такое репрезентативная выборка?
Выборка – это чётко определенное количество респондентов. Её структура должна максимально совпадать со структурой генеральной совокупности по основным характеристикам отбора.
 Например, если потенциальные респонденты – всё население России, где 54% — это женщины, а 46% — мужчины, то выборка должна содержать точно такое же процентное соотношение. Если совпадение параметров происходит, то выборку можно назвать репрезентативной. Это значит, что неточности и ошибки в исследовании сводятся к минимуму.
Например, если потенциальные респонденты – всё население России, где 54% — это женщины, а 46% — мужчины, то выборка должна содержать точно такое же процентное соотношение. Если совпадение параметров происходит, то выборку можно назвать репрезентативной. Это значит, что неточности и ошибки в исследовании сводятся к минимуму.
Объем выборки определяется с учётом требований точности и экономичности. Эти требования обратно пропорциональны друг другу: чем больше объем выборки, тем точнее результат. При этом чем выше точность, тем соответственно больше затрат необходимо на проведение исследования. И наоборот, чем меньше выборка, тем меньше на неё затрат, тем менее точно и более случайно воспроизводятся свойства генеральной совокупности.
Поэтому для вычисления объема выбора социологами была изобретена формула и создан специальный калькулятор :
Доверительная вероятность и доверительная погрешность
Что означают термины «доверительная вероятность » и «доверительная погрешность »? Доверительная вероятность – это показатель точности измерений. А доверительная погрешность – это возможная ошибка результатов исследования. К примеру, при генеральной совокупности более 500 00 человек (допустим, проживающие в Новокузнецке) выборка будет равняться 384 человека при доверительной вероятности 95% и погрешности 5% ИЛИ (при доверительном интервале 95±5%).
Что из этого следует? При проведении 100 исследований с такой выборкой (384 человека) в 95 процентов случаев получаемые ответы по законам статистики будут находиться в пределах ±5% от исходного. И мы получим репрезентативную выборку с минимальной вероятностью статистической ошибки.
После того, как подсчет объема выборки выполнен, можно посмотреть есть ли достаточное число респондентов в демо-версии Панели Анкетолога . А как провести панельный опрос можно подробнее узнать .
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков (пол, возраст, доход, численность, оборот и т.д.), ограниченная в пространстве и времени. Примеры генеральных совокупностей
- Все жители Москвы (10,6 млн. человек по данным переписи 2002 года)
- Мужчины-Москвичи (4,9 млн. человек по данным переписи 2002 года)
- Юридические лица России (2,2 млн. на начало 2005 года)
- Розничные торговые точки, осуществляющие продажу продуктов питания (20 тысяч на начало 2008 года) и т.д.
Выборка (Выборочная совокупность)
Часть объектов из генеральной совокупности, отобранных для изучения, с тем чтобы сделать заключение обо всей генеральной совокупности. Для того чтобы заключение, полученное путем изучения выборки, можно было распространить на всю генеральную совокупность, выборка должна обладать свойством репрезентативности.
Репрезентативность выборки
Свойство выборки корректно отражать генеральную совокупность. Одна и та же выборка может быть репрезентативной и
нерепрезентативной для разных генеральных совокупностей.
Пример:
- Выборка, целиком состоящая из москвичей, владеющих автомобилем, не репрезентирует все население Москвы.
- Выборка из российских предприятий численностью до 100 человек не репрезентирует все предприятия России.
- Выборка из москвичей, совершающих покупки на рынке, не репрезентирует покупательское поведение всех москвичей.
В то же время, указанные выборки (при соблюдении прочих условий) могут отлично репрезентировать
москвичей-автовладельцев, небольшие и средние российские предприятия и покупателей, совершающих покупки на рынках
соответственно.
Важно понимать, что репрезентативность выборки и ошибка выборки – разные явления. Репрезентативность, в отличие от
ошибки никак не зависит от размера выборки.
Пример:
Как бы мы не увеличивали количество опрошенных москвичей-автовладельцев, мы не сможем репрезентировать этой выборкой
всех москвичей.
Ошибка выборки (доверительный интервал)
Отклонение результатов, полученных с помощью выборочного наблюдения от истинных данных генеральной совокупности.
Ошибка выборки бывает двух видов – статистическая и систематическая. Статистическая ошибка зависит от размера
выборки. Чем больше размер выборки, тем она ниже.
Пример:
Для простой случайной выборки размером 400 единиц максимальная статистическая ошибка (с 95% доверительной
вероятностью) составляет 5%, для выборки в 600 единиц – 4%, для выборки в 1100 единиц – 3% Обычно, когда говорят об
ошибке выборки, подразумевают именно статистическую ошибку.
Систематическая ошибка зависит от различных факторов, оказывающих постоянное воздействие на исследование и смещающих
результаты исследования в определенную сторону.
Пример:
- Использование любых вероятностных выборок занижает долю людей с высоким доходом, ведущих активный образ жизни. Происходит это в силу того, что таких людей гораздо сложней застать в каком-либо определенном месте (например, дома).
- Проблема респондентов, отказывающихся отвечать на вопросы (доля «отказников» в Москве, для разных опросов, колеблется от 50% до 80%)
В некоторых случаях, когда известны истинные распределения, систематическую ошибку можно нивелировать введением квот или перевзвешиванием данных, но в большинстве реальных исследований даже оценить ее бывает достаточно проблематично.
Типы выборок
Выборки делятся на два типа:
- вероятностные
- невероятностные
1. Вероятностные выборки
1.1 Случайная выборка (простой случайный отбор)
Такая выборка предполагает однородность генеральной совокупности, одинаковую вероятность доступности всех элементов,
наличие полного списка всех элементов. При отборе элементов, как правило, используется таблица случайных чисел.
1.2 Механическая (систематическая) выборка
Разновидность случайной выборки, упорядоченная по какому-либо признаку (алфавитный порядок, номер телефона, дата
рождения и т.д.). Первый элемент отбирается случайно, затем, с шагом ‘n’ отбирается каждый ‘k’-ый элемент. Размер
генеральной совокупности, при этом – N=n*k
1.3 Стратифицированная (районированная)
Применяется в случае неоднородности генеральной совокупности. Генеральная совокупность разбивается на группы
(страты). В каждой страте отбор осуществляется случайным или механическим образом.
1.4 Серийная (гнездовая или кластерная) выборка
При серийной выборке единицами отбора выступают не сами объекты, а группы (кластеры или гнёзда). Группы отбираются
случайным образом. Объекты внутри групп обследуются сплошняком.
2.Невероятностные выборки
Отбор в такой выборке осуществляется не по принципам случайности, а по субъективным критериям – доступности,
типичности, равного представительства и т.д..
2.1. Квотная выборка
Изначально выделяется некоторое количество групп объектов (например, мужчины в возрасте 20-30 лет, 31-45 лет и 46-60
лет; лица с доходом до 30 тысяч рублей, с доходом от 30 до 60 тысяч рублей и с доходом свыше 60 тысяч рублей) Для
каждой группы задается количество объектов, которые должны быть обследованы. Количество объектов, которые должны
попасть в каждую из групп, задается, чаще всего, либо пропорционально заранее известной доле группы в генеральной
совокупности, либо одинаковым для каждой группы. Внутри групп объекты отбираются произвольно. Квотные выборки
используются в достаточно
часто.
2.2. Метод снежного кома
Выборка строится следующим образом. У каждого респондента, начиная с первого, просятся контакты его друзей, коллег,
знакомых, которые подходили бы под условия отбора и могли бы принять участие в исследовании. Таким образом, за
исключением первого шага, выборка формируется с участием самих объектов исследования. Метод часто применяется, когда
необходимо найти и опросить труднодоступные группы респондентов (например, респондентов, имеющих высокий доход,
респондентов, принадлежащих к одной профессиональной группе, респондентов, имеющих какие-либо схожие хобби/увлечения
и т.д.)
2.3 Стихийная выборка
Опрашиваются наиболее доступные респонденты. Типичные примеры стихийных выборок – в газетах/журналах, отданные респондентам на самозаполнение, большинство
интернет-опросов. Размер и состав стихийных выборок заранее не известен, и определяется только одним параметром –
активностью респондентов.
2.4 Выборка типичных случаев
Отбираются единицы генеральной совокупности, обладающие средним (типичным) значением признака. При этом возникает
проблема выбора признака и определения его типичного значения.
Курс лекций по теории статистики
Более подробную информацию по выборочным наблюдениям можно получить просмотрев .
Интервальное оценивание вероятности события. Формулы расчета численности выборки при собственно-случайном способе отбора.Для определения вероятностей интересующих нас событий мы применяем выборочный метод : проводим n независимых экспериментов, в каждом из которых может произойти (или не произойти) событие А (вероятность р появления события А в каждом эксперименте постоянна). Тогда относительная частота p* появлений событий А в серии из n испытаний принимается в качестве точечной оценки для вероятности p появления события А в отдельном испытании. При этом величину p* называют выборочной долей появлений события А , а р - генеральной долей .
В силу следствия из центральной предельной теоремы (теорема Муавра-Лапласа) относительную частоту события при большом объеме выборки можно считать нормально распределенной с параметрами M(p*)=p и
Поэтому при n>30 доверительный интервал для генеральной доли можно построить, используя формулы:

где u кр находится по таблицам функции Лапласа с учетом заданной доверительной вероятности γ: 2Ф(u кр)=γ.
При малом объеме выборки n≤30 предельная ошибка ε определяется по таблице распределения Стьюдента :
![]() где t кр =t(k; α) и число степеней свободы k=n-1 вероятность α=1-γ (двустороння область).
где t кр =t(k; α) и число степеней свободы k=n-1 вероятность α=1-γ (двустороння область).
Формулы справедливы, если отбор проводился случайным повторным образом (генеральная совокупность бесконечна), в противном случае необходимо сделать поправку на бесповторность отбора (таблица).
Средняя ошибка выборки для генеральной доли
| Генеральная совокупность | Бесконечная | Конечная объема N |
| Тип отбора | Повторный | Бесповторный |
| Средняя ошибка выборки |
Формулы расчета численности выборки при собственно-случайном способе отбора
| Способ отбора | Формулы определения численности выборки | ||
| для средней | для доли | ||
| Повторный | |||
| Бесповторный | |||
Задачи о генеральной доле
На вопрос «Накрывает ли доверительный интервал заданное значение p 0 ?» - можно ответить, проверив статистическую гипотезу H 0:p=p 0 . При этом предполагается, что опыты проводятся по схеме испытаний Бернулли (независимы, вероятность p появления события А постоянна). По выборке объема n определяют относительную частоту p * появления события A: где m - количество появлений события А в серии из n испытаний. Для проверки гипотезы H 0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).Таблица 1 - Гипотезы о генеральной доле
Гипотеза | H 0:p=p 0 | H 0:p 1 =p 2 |
| Предположения | Схема испытаний Бернулли | Схема испытаний Бернулли |
| Оценки по выборке | 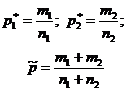 |
|
| Статистика K |  |  |
| Распределение статистики K | Стандартное нормальное N(0,1) |
Пример №1
. С помощью случайного повторного отбора руководство фирмы провело выборочный опрос 900 своих служащих. Среди опрошенных оказалось 270 женщин. Постройте доверительный интервал , с вероятностью 0.95 накрывающий истинную долю женщин во всем коллективе фирмы.
Решение. По условию выборочная доля женщин составляет (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
![]()
Значение u кр находим по таблице функции Лапласа из соотношения 2Ф(u кр)=γ, т.е. ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при u кр =1.96. Следовательно, предельная ошибка
Функция Лапласа (приложение 1) принимает значение 0.475 при u кр =1.96. Следовательно, предельная ошибка ![]() и искомый доверительный интервал
и искомый доверительный интервал
(p – ε, p + ε) = (0.3 – 0.18; 0.3 + 0.18) = (0.12; 0.48)
Итак, с вероятностью 0.95 можно гарантировать, что доля женщин во всем коллективе фирмы находится в интервале от 0.12 до 0.48.
Пример №2
. Владелец автостоянки считает день «удачным», если автостоянка заполнена более, чем на 80 %. В течение года было проведено 40 проверок автостоянки, из которых 24 оказались «удачными». С вероятностью 0.98 найдите доверительный интервал для оценки истинной доли «удачных» дней в течение года.
Решение
. Выборочная доля «удачных» дней составляет
По таблице функции Лапласа найдем значение u кр при заданной
доверительной вероятности
Ф(2.23) = 0.49, u кр = 2.33.
Считая отбор бесповторным (т.е. две проверки в один день не проводилось), найдем предельную ошибку: ![]()
где n=40 , N = 365 (дней). Отсюда ![]()
и доверительный интервал для генеральной доли: (p – ε, p + ε) = (0.6 – 0.17; 0.6 + 0.17) = (0.43; 0.77)
С вероятностью 0.98 можно ожидать, что доля «удачных» дней в течение года находится в интервале от 0.43 до 0.77.
Пример №3
. Проверив 2500 изделий в партии, обнаружили, что 400 изделий высшего сорта, а n–m – нет. Сколько надо проверить изделий, чтобы с уверенностью 95% определить долю высшего сорта с точностью до 0.01 ?
Решение ищем по формуле определения численности выборки для повторного отбора.
Ф(t) = γ/2 = 0.95/2 = 0.475 и этому значению по таблице Лапласа соответствует t=1.96
Выборочная доля w = 0.16; ошибка выборки ε = 0.01
Пример №4
. Партия изделий принимается, если вероятность того, что изделие окажется соответствующим стандарту, составляет не менее 0.97. Среди случайно отобранных 200 изделий проверяемой партии оказалось 193 соответствующих стандарту. Можно ли на уровне значимости α=0,02 принять партию?
Решение
. Сформулируем основную и альтернативную гипотезы.
H 0:p=p 0 =0,97 - неизвестная генеральная доля p
равна заданному значению p 0 =0,97. Применительно к условию - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, равна 0.97; т.е. партию изделий можно принять.
H 1:p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдаемое значение статистики K
(таблица) вычислим при заданных значениях p 0 =0,97, n=200, m=193

Критическое значение находим по таблице функции Лапласа из равенства
![]()
По условию α=0,02 отсюда Ф(Ккр)=0,48 и Ккр=2,05. Критическая область левосторонняя, т.е. является интервалом (-∞;-K kp)= (-∞;-2,05). Наблюдаемое значение К набл =-0,415 не принадлежит критической области, следовательно, на данном уровне значимости нет оснований отклонять основную гипотезу. Партию изделий принять можно.
Пример №5
. Два завода изготавливают однотипные детали. Для оценки их качества сделаны выборки из продукции этих заводов и получены следующие результаты. Среди 200 отобранных изделий первого завода оказалось 20 бракованных, среди 300 изделий второго завода - 15 бракованных.
На уровне значимости 0.025 выяснить, имеется ли существенное различие в качестве изготавливаемых этими заводами деталей.
По условию α=0,025 отсюда Ф(Ккр)=0,4875 и Ккр=2,24. При двусторонней альтернативе область допустимых значений имеет вид (-2,24;2,24). Наблюдаемое значение K набл =2,15 попадает в этот интервал, т.е. на данном уровне значимости нет оснований отвергать основную гипотезу. Заводы изготавливают изделия одинакового качества.
Тема: Выборочный метод в статистике
1. Понятие о выборочном наблюдении, его задачи
Статистическое наблюдение можно организовать сплошное и несплошное. Сплошное наблюдение предусматривает обследование всех единиц изучаемой совокупности и связано с большими трудовыми и материальными затратами. Изучение не всех единиц совокупности, а лишь некоторой части, по которой следует судить о свойствах всей совокупности в целом, можно осуществить несплошным наблюдением. В статистической практике самым распространенным является выборочное наблюдение.
Выборочное наблюдение - это такой вид несплошного наблюдения, при котором отбор подлежащих обследованию единиц осуществляется в случайном порядке, отобранная часть изучается, а результаты распространяются на всю исходную совокупность. Наблюдение организуется таким образом, что эта часть отобранных единиц в уменьшенном масштабе репрезентирует (представляет) всю совокупность.
Совокупность, из которой производится отбор, называется генеральной, генеральными.
Совокупность отобранных единиц именуют выборочной совокупностью, и все ее обобщающие показатели - выборочными.
Имеется ряд причин, в силу которых, во многих случаях выборочному наблюдению отдается предпочтение перед сплошным. Наиболее существенны из них следующие:
Экономия времени и средств в результате сокращения объема работы;
Сведение к минимуму порчи или уничтожения исследуемых объектов (определение прочности пряжи при разрыве, испытание электрических лампочек на продолжительность горения, проверка консервов на доброкачественность);
Необходимость детального исследования каждой единицы наблюдения при невозможности охвата всех единиц (при изучении бюджета семей);
Достижение большой точности результатов обследования благодаря сокращению ошибок, происходящих при регистрации.
Преимущество выборочного наблюдения по сравнению со сплошным можно реализовать, если оно организовано и проведено в строгом соответствии с научными принципами теории выборочного метода. Такими принципами являются: обеспечение случайности (равной возможности попадания в выборку) отбора единиц и достаточного их числа. Соблюдение этих принципов позволяет получить объективную гарантию репрезентативности полученной выборочной совокупности. Понятие репрезентативности отобранной совокупности не следует понимать как ее представительство по всем признакам изучаемой совокупности, а только в отношении тех признаков, которые изучаются или оказывают существенное влияние на формирование сводных обобщающих характеристик.
Основная задача выборочного наблюдения в экономике состоит в том, чтобы на основе характеристик выборочной совокупности (средней и доли) получить достоверные суждения о показателях средней и доли в генеральной совокупности. При этом следует иметь в виду, что при любых статистических исследованиях (сплошных и выборочных) возникают ошибки двух видов: регистрации и репрезентативности.
Ошибки регистрации могут иметь случайный (непреднамеренный) и систематический (тенденциозный) характер. Случайные ошибки обычно уравновешивают друг друга, поскольку не имеют преимущественного направления в сторону преувеличения или преуменьшения значения изучаемого показателя. Систематические ошибки направлены в одну сторону вследствие преднамеренного нарушения правил отбора (предвзятые цели). Их можно избежать при правильной организации и проведении наблюдения.
Ошибки репрезентативности присущи только выборочному наблюдению и возникают в силу того, что выборочная совокупность не полностью воспроизводит генеральную. Они представляют собой расхождение между значениями показателей, полученных по выборке, и значениями показателей этих же величин, которые были бы получены при проведенном с одинаковой степенью точности сплошном наблюдении, т. е. между величинами выборных и соответствующих генеральных показателей.
Для каждого конкретного выборочного наблюдения значение ошибки репрезентативности может быть определено по соответствующим формулам, которые зависят от вида, метода и способа формирования выборочной совокупности.
По виду различают индивидуальный, групповой и комбинированный отбор. При индивидуальном отборе в выборочную совокупность отбираются отдельные единицы генеральной совокупности; при групповом отборе - качественно однородные группы или серии изучаемых единиц; комбинированный отбор предполагает сочетание первого и второго видов.
По методу отбора различают повторную и бесповторную выборки.
При повторной выборке общая численность единиц генеральной совокупности в процессе выборки остается неизменной. Ту или иную единицу, попавшую в выборку, после регистрации снова возвращают в генеральную совокупность, и она сохраняет равную возможность со всеми прочими единицами при повторном отборе единиц вновь попасть в выборку («отбор по схеме возвращенного шара»). Повторная выборка в социально-экономической жизни встречается редко. Обычно выборку организуют по схеме бесповторной выборки.
При бесповторной выборке единица совокупности, попавшая в выборку, в генеральную совокупность не возвращается и в дальнейшем в выборке не участвует; т. е. последующую выборку делают из генеральной совокупности уже без отобранных ранее единиц («отбор по схеме невозвращенного шара»). Таким образом, при бесповторной выборке численность единиц генеральной совокупности сокращается в процессе исследования.
Способ отбора определяет конкретный механизм или процедуру выборки единиц из генеральной совокупности.
По степени охвата единиц совокупности различают большие и малые (n <30) выборки.
В практике выборочных исследований наибольшее распространение получили следующие виды выборки: собственно-случайная, механическая, типическая, серийная, комбинированная.
Основные характеристики параметров генеральной и выборочной совокупностей обозначаются символами:
N-объем генеральной совокупности (число входящих в нее единиц);
п - объем выборки (число обследованных единиц);
- генеральная средняя (среднее значение признака в генеральной совокупности);
Выборочная средняя;
P - генеральная доля (доля единиц, обладающих данным значением признака в общем числе единиц генеральной совокупности);
w - выборочная доля;
- генеральная дисперсия (дисперсия признака в генеральной совокупности);
S 2 - выборочная дисперсия того же признака;
- среднее квадратическое отклонение в генеральной совокупности;
S - среднее квадратическое отклонение в выборке.
2. Ошибки выборки
При выборочном наблюдении должна быть обеспечена случайность отбора единиц. Каждая единица должна иметь равную с другими возможность быть отобранной. Именно на этом основывается собственно-случайная выборка.
К собственно-случайной выборке относится отбор единиц из всей генеральной совокупности (без предварительного расчленения ее на какие-либо группы) посредством жеребьевки (преимущественно) или какого-либо иного подобного способа, например, с помощью таблицы случайных чисел. Случайный отбор - это отбор не беспорядочный. Принцип случайности предполагает, что на включение или исключение объекта из выборки не может повлиять какой-либо фактор, кроме случая. Примером собственно-случайного отбора могут служить тиражи выигрышей: из общего количества выпущенных билетов наугад отбирается определенная часть номеров, на которые приходятся выигрыши. Причем всем номерам обеспечивается равная возможность попадания в выборку. При этом количество отобранных в выборочную совокупность единиц обычно определяется исходя из принятой доли выборки.
Доля, выборки есть отношение числа единиц выборочной совокупности к числу единиц генеральной совокупности:
![]()
Так, при 5%-ной выборке из партии деталей в 1000 ед. объем выборки п составляет 50 ед., а при 10%-ной выборке -100 ед. и т.д. При правильной научной организации выборки ошибки репрезентативности можно свести к минимальном значениям, в результате - выборочное наблюдение становится достаточно точным.
Собственно-случайный отбор «в чистом виде» применяется в практике выборочного наблюдения редко, но он является исходным среди всех других видов отбора, в нем заключаются и реализуются основные принципы выборочного наблюдения.
Рассмотрим некоторые вопросы теории выборочного метода и формулы ошибок для простой случайной выборки.
Применяя выборочный метод в статистике, обычно используют два основных вида обобщающих показателей: среднюю величину количественного признака и относительную величину альтернативного признака (долю или удельный вес единиц в статистической совокупности, которые отличаются от всех других единиц этой совокупности только наличием изучаемого признака).
Выборочная доля ( w ), или частость, определяется отношением числа единиц, обладающих изучаемым признаком т, к общему числу единиц выборочной совокупности п:
w = т/п.
Например, если из 100 деталей выборки (и = 100), 95 деталей оказались стандартными (т =95), то выборочная доля
w = 95 / 100 = 0,95 .
Для характеристики надежности выборочных показателей различают среднюю и предельную ошибки выборки.
Ошибка выборки или, иначе говоря, ошибка репрезентативности представляет собой разность соответствующих выборочных и генеральных характеристик:
![]() (1)
(1)
![]() (2)
(2)
Ошибка выборки свойственна только выборочным наблюдениям. Чем больше значение этой ошибки, тем в большей степени выборочные показатели отличаются от соответствующих генеральных показателей.
Выборочная средняя и выборочная доля по своей сути являются случайными величинами, которые могут принимать различные значения в зависимости от того, какие единицы совокупности попали в выборку. Следовательно, ошибки выборки также являются случайными величинами и могут принимать различные значения. Поэтому определяют среднюю из возможных ошибок - среднюю ошибку выборки.
От чего зависит средняя ошибка выборки! При соблюдении принципа случайного отбора средняя ошибка выборки определяется, прежде всего объемом выборки: чем больше численность при прочих равных условиях, тем меньше величина средней ошибки выборки. Охватывая выборочным обследованием все большее количество единиц генеральной совокупности, всё более точно характеризуем всю генеральную совокупность.
Средняя ошибка выборки также зависит от степени варьирования изучаемого признака. Степень варьирования, как известно, характеризуется дисперсией или w (1 - w ) - для альтернативного признака. Чем меньше вариация признака, а следовательно, и дисперсия, тем меньше средняя ошибка выборки, и наоборот. При нулевой дисперсии (признак не варьирует) средняя ошибка выборки равна нулю, т. е. любая единица генеральной совокупности будет совершенно точно характеризовать всю совокупность по этому признаку.
Зависимость средней ошибки выборки от ее объема и степени варьирования признака отражена в формулах, с помощью которых можно рассчитать среднюю ошибку выборки в условиях выборочного наблюдения, когда генеральные характеристики (х,р) неизвестны, и следовательно, не представляется возможным нахождение реальной ошибки выборки непосредственно по формулам (1), (2).
При случайном повторном отборе средние ошибки теоретически рассчитывают по следующим формулам:
для средней количественного признака
![]() (3)
(3)
для доли (альтернативного признака)
![]() (4)
(4)
Поскольку практически дисперсия признака в генеральной совокупности точно неизвестна, на практике пользуются
значением дисперсии S 2 , рассчитанным для выборочной совокупности на основании закона больших чисел, согласно которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
Таким образом, расчетные формулы средней ошибки выборки при случайном повторном отборе будут следующие:
для средней количественного признака
для доли (альтернативного признака)
![]() (6)
(6)
Однако дисперсия выборочной совокупности не равна дисперсии генеральной совокупности, и следовательно, средние ошибки выборки, рассчитанные по формулам (5) и (6), будут приближенными. Но в теории вероятностей доказано, что генеральная дисперсия выражается через выборочную следующим соотношением:
![]() (7)
(7)
Так как п / (n -1) при достаточно больших п - величина, близкая к единице, то можно принять, что = S 2 , а следовательно, в практических расчетах средних ошибок выборки можно использовать формулы (5) и (6). И только в случаях малой выборки (когда объем выборки не превышает 30) необходимо учитывать коэффициент п/(п-1) и исчислять среднюю ошибку малой выборки по формуле:
 (8)
(8)
в приведенные выше формулы расчета средних ошибок выборки необходимо подкоренное выражение умножить на 1-(п/ N ), поскольку в процессе бесповторной выборки сокращается численность единиц генеральной совокупности. Следовательно, для бесповторной выборки расчетные формулы средней ошибки выборки примут такой вид:
для средней количественного признака
 (9)
(9)
для доли (альтернативного признака)
![]() (10)
(10)
Так как п всегда меньше N , то дополнительный множитель 1 - (n / N ) всегда будет меньше единицы. Отсюда следует, что средняя ошибка при бесповторном отборе всегда будет меньше, чем при повторном. В то же время при сравнительно небольшом проценте выборки этот множитель близок к единице (например, при 5%-ной выборке он равен 0,95; при 2%-ной - 0,98 и т.д.). Поэтому иногда на практике пользуются для определения средней ошибки выборки формулами (5) и (6) без указанного множителя, хотя выборку и организуют как бесповторную. Это имеет место в тех случаях, когда число единиц генеральной совокупности N неизвестно или безгранично, или когда п очень мало по сравнению с N, и по существу, введение дополнительного множителя, близкого по значению к единице, практически не повлияет на значение средней ошибки выборки.
Механическая выборка состоит в том, что отбор единиц в выборочную совокупность из генеральной, разбитой по нейтральному признаку на равные интервалы (группы), производится таким образом, что из каждой такой группы в выборку отбирается лишь одна единица. Чтобы избежать систематической ошибки, отбираться должна единица, которая находится в середине каждой группы.
При организации механического отбора единицы совокупности предварительно располагают (обычно в списке) в определенном порядке (например, по алфавиту, местоположению, в порядке возрастания или убывания значений какого-либо показателя, не связанного с изучаемым свойством, и т.д.), после чего отбирают заданное число единиц механически, через определенный итервал. При этом размер интервала в генеральной совокупности равен обратному значению доли выборки. Так, при 2%-ной выборке отбирается и проверяется каждая 50-я единица (1: 0,02), при 5 %-ной выборке - каждая 20-я единица (1: 0,05), например, сходящая со станка деталь.
При достаточно большой совокупности механический отбор по точности результатов близок к собственно-случайному. Поэтому для определения средней ошибки механической выборки используют формулы собственно-случайной бесповторной выборки (9), (10).
Для отбора единиц из неоднородной совокупности применяется, так называемая типическая выборка, которая используется в тех случаях, когда все единицы генеральной совокупности можно разбить на несколько качественно однородных, однотипных групп по признакам, влияющим на изучаемые показатели.
При обследовании предприятий такими группами могут быть, например, отрасль и подотрасль, формы собственности. Затем из каждой типической группы собственно-случайной или механической выборкой производится индивидуальный отбор единиц в выборочную совокупность.
Типическая выборка обычно применяется при изучении сложных статистических совокупностей. Например, при выборочном обследовании семейных бюджетов рабочих и служащих в отдельных отраслях экономики, производительности труда рабочих предприятия, представленных отдельными группами по квалификации.
Типическая выборка дает более точные результаты по сравнению с другими способами отбора единиц в выборочную совокупность. Типизация генеральной совокупности обеспечивает репрезентативность такой выборки, представительство в ней каждой типологической группы, что позволяет исключить влияние межгрупповой дисперсии на среднюю ошибку выборки,
При определении средней ошибки типической выборки в качестве показателя вариации выступает средняя из внутригрупповых дисперсий.
Среднюю ошибку выборки находят по формулам:
для средней количественного признака
(повторный отбор); (11)
 (бесповторный отбор); (
12)
(бесповторный отбор); (
12)
для доли (альтернативного признака)
![]() (повторный отбор); (13)
(повторный отбор); (13)
 (бесповторный отбор), (14)
(бесповторный отбор), (14)
где - средняя из внутригрупповых дисперсий по выборочной совокупности;
Средняя из внутригрупповых дисперсий доли (альтернативного
признака) по выборочной совокупности.
Серийная выборка предполагает случайный отбор из генеральной совокупности не отдельных единиц, а их равновеликих групп (гнезд, серий) с тем, чтобы в таких группах подвергать наблюдению все без исключения единицы.
Применение серийной выборки обусловлено тем, что многие товары для их транспортировки, хранения и продажи упаковываются в пачки, ящики и т.п. Поэтому при контроле качества упакованного товара рациональнее проверить несколько упаковок (серий), чем из всех упаковок отбирать необходимое количество товара.
Поскольку внутри групп (серий) обследуются все без исключения единицы, средняя ошибка выборки (при отборе равновеликих серий) зависит только от межгрупповой (межсерийной) дисперсии.
Среднюю ошибку выборки для средней количественного признака при серийном отборе находят по формулам:
(повторный отбор); (15 )
![]() (бесповторный отбор), (16
)
(бесповторный отбор), (16
)
где r - число отобранных серий; R - общее число серий.
Межгрупповую дисперсию серийной выборки вычисляют следующим образом:![]()
где - средняя i-й серии; - общая средняя по всей выборочной совокупности.
Средняя ошибка выборки для доли (альтернативного признака) при серийном отборе:
![]() (повторный отбор); (17
)
(повторный отбор); (17
)
 (бесповторный отбор). (18
)
(бесповторный отбор). (18
)
Межгрупповую (межсерийную) дисперсию доли серийной выборки определяют по формуле:
![]() (19)
(19)
где w i - доля признака в i-и серии; - общая доля признака во всей выборочной совокупности.
В практике статистических обследований помимо рассмотренных ранее способов отбора применяется их комбинация (комбинированный отбор).
3. Распространение выборочных результатов на генеральную совокупность
Конечной целью выборочного наблюдения является характеристика генеральной совокупности на основе выборочных результатов.
Выборочные средние и относительные величины распространяют на генеральную совокупность с учетом предела их возможной ошибки.
В каждой конкретной выборке расхождение между выборочной средней и генеральной, т. е. может быть меньше средней ошибки выборки , равно ей или больше ее.
Причем каждое из этих расхождений имеет различную вероятность (объективную возможность появления события). Поэтому фактические расхождения между выборочной средней и генеральной можно рассматривать как некую предельную ошибку, связанную со средней ошибкой и гарантируемую с определенной вероятностью Р.
Предельную ошибку выборки для средней () при повторном отборе можно рассчитать по формуле:
 (20)
(20)
где t - нормированное отклонение - «коэффициент доверия», зависящий от вероятности, с которой гарантируется предельная ошибка выборки;
Средняя ошибка выборки.
Аналогичным образом может быть записана формула предельной ошибки выборки для доли при повторном отборе:
![]() (21)
(21)
При случайном бесповторном отборе в формулах расчета предельных ошибок выборки (20) и (21) необходимо умножить подкоренное выражение на 1 - (n / N ) .
Формула предельной ошибки выборки вытекает из основных положений теории выборочного метода, сформулированных в ряде теорем теории вероятностей, отражающих закон больших чисел.
На основании теоремы П.Л. Чебышева (с уточнениями А.М. Ляпунова) с вероятностью, сколь угодно близкой к единице, можно утверждать, что при достаточно большом объеме выборки и ограниченной генеральной дисперсии выборочные обобщающие показатели (средняя, доля) будут сколь угодно мало отличаться от соответствующих генеральных показателей.
Применительно к нахождению среднего значения признака эта теорема может быть записана так:
![]() (22)
(22)
а для доли признака:
![]() (23
)
(23
)
где (24)
(24)
Таким образом, величина предельной ошибки выборки может быть установлена с определенной вероятностью.
Значения функции Ф( t ) при различных значениях t как коэффициента кратности средней ошибки выборки, определяются на основе специально составленных таблиц. Приведем некоторые значения, применяемые наиболее часто для выборок достаточно большого объема (n 30):
t 1,000 1,960 2,000 2,580 3,000
Ф( t ) 0,683 0,950 0,954 0,990 0,997
Предельная ошибка выборки отвечает на вопрос о точности выборки с определенной вероятностью, значение которой определяется коэффициентом t (в практических расчетах, как правило, заданная вероятность не должна быть менее 0,95). Так, при t = 1 предельная ошибка составит = . Следовательно, с вероятностью 0,683 можно утверждать, что разность между выборочными и генеральными показателями не превысит одной средней ошибки выборки. Другими словами, в 68,3% случаев ошибка репрезентативности не выйдет за пределы ±1.
При t = 2 с вероятностью 0,954 она не выйдет за пределы ±2 ,
при t = 3 с вероятностью 0,997 - за пределы ±3 и т.д.
Как видно из приведённых выше значений функции Ф (t ) (см. последнее значение), вероятность появления ошибки, равной или большей утроенной средней ошибки выборки, т. е. 3 крайне мала и равна 0,003, т. е. 1-0,997. Такие маловероятные события считаются практически невозможными, а потому величину = 3можно принять за предел возможной ошибки выборки.
Выборочное наблюдение проводится в целях распространения выводов, полученных по данным выборки, на генеральную совокупность. Одной из основных задач является оценка по данным выборки исследуемых характеристик (параметров) генеральной совокупности.
Предельная ошибка выборки позволяет определить предельные значения характеристик генеральной совокупности и их доверительные интервалы:
для средней (25)
для доли (26)
Это означает, что с заданной вероятностью можно утверждать, что значение генеральной средней следует ожидать в пределах от - до +
Аналогичным образом может быть записан доверительный интервал генеральной доли:![]()
Наряду с абсолютным значением предельной ошибки выборки рассчитывается и предельная относительная ошибка выборки, которая определяется как процентное отношение предельной ошибки выборки к соответствующей характеристике выборочной совокупности:
для средней, %:![]() (27)
(27)
для доли, %: (28)
Рассмотрим нахождение средних и предельных ошибок выборки, определение доверительных пределов средней и доли на конкретных примерах.
Задача 1. Для определения скорости расчетов с кредиторами предприятий корпорации в коммерческом банке была проведена случайная выборка 100 платежных документов, по которым средний срок перечисления и получения денег оказался равным 22 дням ( = 22) со стандартным отклонением 6 дней (S= 6).
Необходимо с вероятностью Р = 0,954 определить предельную ошибку выборочной средней и доверительные пределы средней продолжительности расчетов предприятий данной корпорации.
Решение. Предельную ошибку = t определяем по формуле повторного отбора (6.20), так как численность генеральной совокупности N неизвестна. Из представленных значений Ф (t ) (см. с. 98) для вероятности Р = 0,954 находим t = 2.
Следовательно, предельная ошибка выборки, дней:
![]()
![]()
Генеральная средняя будет равна = ± , а доверительные интервалы (пределы) генеральной средней исчисляем, исходя из двойного неравенства:
![]()
![]()
Таким образом, с вероятностью 0,954 можно утверждать, что средняя продолжительность расчетов предприятий данной корпорации колеблется в пределах от 20,8 до 23,2 дней.
Задача 2. Среди выборочно обследованных 1000 семей региона по уровню душевого дохода (выборка 2%-ная, механическая) малообеспеченных оказалось 300 семей.
Требуется с вероятностью 0,997 определить долю малообеспеченных семей во всем регионе.
Решение. Выборочная доля (доля малообеспеченных семей среди обследованных семей) равна:
По представленным ранее данным Ф(t ) для вероятности 0,997 находим t = 3 (см. с. 99). Предельную ошибку доли определяем по формуле бесповторного отбора (механическая выборка всегда является бесповторной):
Предельная относительная ошибка выборки, %:
Генеральная доляа доверительные пределы генеральной доли исчисляем, исходя из двойного неравенства:
В нашем примере:
Таким образом, почти достоверно, с вероятностью 0,997 можно утверждать, что доля малообеспеченных семей среди всех семей региона колеблется от 28,6 до 31,4%.
Задача 3. Для определения урожайности зерновых культур проведено выборочное обследование 100 хозяйств региона различных форм собственности, в результате которого получены сводные данные (табл.6.1). Необходимо с вероятностью 0,954 определить предельную ошибку выборочной средней и доверительные пределы средней урожайности зерновых культур по всем хозяйствам региона.
Таблица 6.1
Распределение урожайности по хозяйствам региона, имеющим различную форму собственности
Решение. Поскольку обследованные хозяйства региона сгруппированы по формам собственности, предельную ошибку средней урожайности определяем по формуле для типической выборки, осуществляемой методом повторного отбора (численность генеральной совокупности N неизвестна):
В этой формуле неизвестна средняя из внутригрупповых дисперсий.
Она исчисляется по формуле:
По представленным ранее (см. с. 98) данным Ф (t ) для вероятности Р =0,954 находим t = 2.
Тогда предельная ошибка выборки, ц/га:

Генеральная средняя: = ± . Для нахождения ее границ вначале нужно исчислить среднюю урожайность по выборочной совокупности , ц/га:
Предельная относительная ошибка выборки, %:
![]()
Доверительные пределы генеральной средней исчисляем, исходя из двойного неравенства:
![]()
Таким образом, с вероятностью 0,954 можно гарантировать, что средняя урожайность зерновых культур по региону будет не менее чем 20 ц/га, но и не более чем 22 ц/га.
Определение необходимого объема выборки. При проектировании выборочного наблюдения с заранее заданным значением допустимой ошибки выборки очень важно правильно определить численность (объем) выборочной совокупности, которая с определенной вероятностью обеспечит заданную точность результатов наблюдения. Формулы для определения необходимой численности выборки п легко получить непосредственно из формул ошибок выборки.
Так, из формул предельной ошибки выборки для повторного отбора нетрудно (предварительно возведя в квадрат обе части равенства) выразить необходимую численность выборки:
для средней количественного признака
для доли (альтернативного признака)
![]() (30
)
(30
)
Аналогично из формул предельной ошибки выборки для бесповторного отбора находим, что
 (для средней);
(31
)
(для средней);
(31
)
 (для доли).
(32
)
(для доли).
(32
)
Эти формулы показывают, что с увеличением предполагаемой ошибки выборки значительно уменьшается необходимый объем выборки.
Для расчета объема выборки нужно знать дисперсию. Она может быть заимствована из проводимых ранее обследований данной или аналогичной совокупности, а если таковых нет, тогда для определения дисперсии надо провести специальное выборочное обследование небольшого объема.
Задача 4. Для определения среднего возраста 1200 студентов факультета необходимо провести выборочное обследование методом случайного бесповторного отбора. Предварительно установлено, что среднее квадратическое отклонение возраста студентов равно 10 годам.
Сколько студентов нужно обследовать, чтобы с вероятностью 0,954 средняя ошибка выборки не превышала 3 года?
Решение. Рассчитаем необходимую численность выборки, чел., по формуле бесповторного отбора (6.31), учитывая, что t = 2 при Р = 0,954:
Таким образом, выборка численностью 47 чел. обеспечивает заданную точность при бесповторном отборе.
Выборочный метод широко используется в статистической практике для получения экономической информации.
Большую актуальность приобретает выборочный метод в современных условиях перехода к рыночной экономике. Изменения в характере экономических отношений, аренда, собственность отдельных коллективов и лиц обусловливают изменения функций учета и статистики, сокращение и упрощение отчетности. Вместе с тем, возрастающие требования к менеджменту усиливают потребность в обеспечении надежной информацией, дальнейшего повышения ее оперативности. Все это обусловливает более широкое применение выборочного метода в экономике.
В отечественной статистике уже накоплен определенный опыт выборочных обследований.